僷僜僐儞偺暥帤張棟偼乽暥帤僐乕僪乿偲乽暥帤僼僅儞僩乿偲偄偆巇慻傒傪拞怱偵偍偙側偄傑偡丅偙傟傜偺愝掕偵怘偄堘偄偑惗偠偡傞偲暥帤壔偗傗暥帤敳偗偲偄偆忬懺偑婲偒傑偡丅僩儔僽儖偵懳張偡傞偨傔偵偼,擔杮岅暥帤昞帵偺巇慻傒偵偮偄偰昁梫嵟掅尷偺抦幆偑昁梫偵側傝傑偡丅億僀儞僩偼乽暥帤僐乕僪乿傗乽暥帤僼僅儞僩乿偵偼暋悢偺婯奿偑偁傝,偙傟傜傪愝掕偱曄峏偱偒傞傛偆偵側偭偰偄傞偙偲偱偡丅
暥帤敳偗傗暥帤壔偼乽暥帤僐乕僪乿偺栤戣偩偗偱婲偒傞尰徾偱偼偁傝傑偣傫丅巊梡暥帤僐乕僪偲懳墳偡傞僼僅儞僩乮帤宍忣曬乯偲偄偆栤戣偑偁傝傑偡丅Windows XP偐傜Windows Vista偵傾僢僾僌儗乕僪偡傞偲偒偵偼栤戣偑婲偒傑偟偨丅徻偟偔偼乽僼僅儞僩乿偺儁乕僕傪偛棗偔偩偝偄丅
傑偨,昞帵惂屼偺僔僗僥儉僼傽僀儖偑嶍彍偝傟偨傝,怴偟偄僼傽僀儖偑屆偄傕偺偵忋彂偒偝傟偨傝偟偰傕婲偒傑偡丅僨乕僞僼傽僀儖偑晹暘揑偵夡傟偨応崌傗僨乕僞夵鈧僞僀僾偺僂僀儖僗偵姶愼偟偨応崌偵傕側傝傑偡丅
乽暥帤僐乕僪乿偲偼
僐儞僺儏乕僞偺婎慴昞尰偼俀恑悢偺僐乕僪乮晞崋乯偱偡丅僐儞僺儏乕僞偱暥帤傪庢傝埖偊傞傛偆偵偡傞偵偼,暥帤傂偲偮傂偲偮傪偳偺傛偆側僐乕僪乮晞崋乯偱昞偡偐傪寛傔傞昁梫偑偁傝傑偡丅偙偺僐乕僪乮晞崋乯妱傝怳傝婯奿傪乽暥帤僐乕僪懱宯乿傑偨偼扨偵乽暥帤僐乕僪乿偲偄偄傑偡丅
丂乽暥帤僐乕僪乿傪16恑悢偺暥帤僐乕僪斣崋偱堦棗昞偵偟偨傕偺傪乽暥帤僐乕僪昞乿偲偄偄傑偡丅捠忢,乽暥帤僐乕僪昞乿偼16恑悢斣崋偵傛傞儅僩儕僢僋僗偱偁傜傢偟傑偡丅
壓恾偼MS-IME偺IME僷僢僪偺僔僼僩JIS僐乕僪偺暥帤堦棗偺僂僀儞僪僂偱偡丅忋晹,墶偵暲傫偱偄傞乽0123456789ABCDE乿偼16恑僐乕僪偺堦寘栚偱偡丅廲偵暲傫偱偄傞乽8240,8250,8260, 乧乿偑懠偺晹暘傪昞偟傑偡丅僐乕僪乽824F乿偼悢帤偺乽0乿,僐乕僪乽8250乿偼悢帤偺乽1乿,僐乕僪乽8251乿偼悢帤偺乽2乿,僐乕僪乽8260乿偼塸戝暥帤偺乽A乿,僐乕僪乽83401乿偼僇僞僇僫乽傽乿偱偡丅
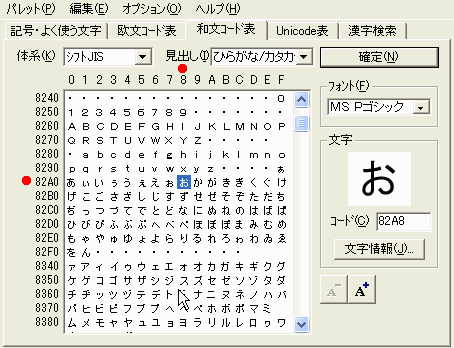
乽僷僜僐儞暥帤僐乕僪帿揟乿偲偼暥帤偛偲偵偦偺暥帤懱宯偛偲偺暥帤僐乕僪斣崋傪柧婰偟偨帿揟偱偡丅嵟嬤偼捠忢偺崙岅帠揟傗娍榓帿揟偱傕僷僜僐儞偺暥帤僐乕僪偑婰嵹偝偰偄傑偡丅
乽暥帤僐乕僪懱宯乿偺婯奿偼暋悢偁傝傑偡
僷僜僐儞偼墷暷偱敪揥偟偨傕偺偱偡偺偱,僷僜僐儞偑8價僢僩偺帪戙偼暷崙偺ASCII(傾僗僉乕)僐乕僪傪拞怱偵巊偄傑偟偨丅16價僢僩僷僜僐儞偺搊応偵傛傝,擔杮傪偼偠傔偄傠偄傠側抧堟尵岅偵懳墳偑壜擻偵側傝,偦偺抧堟尵岅偱偺暥帤僐乕僪懱宯偑嶔掕偝傟傑偟偨丅
偨偩偟,暥帤僐乕僪懱宯偵巊偊傞僐乕僪乮晞崋乯偵偼婯掕乮斖埻惂尷乯偑偁傞偨傔,乽堎側傞抧堟偺傕偺偲僐乕僪偑廳暋偡傞乿乽摨偠尵岅偱傕嶔掕偡傞抍懱傗婡娭偵傛傝暥帤僐乕僪懱宯偑堎側傞乿側偳偺栤戣偑偁傝傑偟偨丅
尰嵼偼,崙嵺婯奿偺暥帤僐乕僪懱宯偺嶔掕偑ISO乮崙嵺昗弨壔婡峔乯偱峴傢傟偰偄傑偡丅婎杮僜僼僩偺Windows偱偼XP傑偱僔僼僩JIS傪昗弨偲偟偰偒傑偟偨偑,尰嵼偺Windows偱偼乽Unicode(儐僯僐乕僪)乿偺乽UTF-8乿婯奿偑昗弨偲側偭偰偄傑偡丅
Windows暥帤僐乕僪偺昗弨偲偼昗弨揑偵巊偆偲偄偆偙偲偱偦傟偟偐巊偊側偄偲偄偆偙偲偱偼偁傝傑偣傫丅彮偟愱栧揑偵側傝傑偡偑,撪晹張棟偱偼Windows暥帤僐乕僪偼埲慜偐傜乽Unicode(儐僯僐乕僪)乿偑巊傢傟偰偄傑偡偑,夁嫀偲屳姺惈傪帩偨偣傞偨傔,撪晹偱帺摦揑偵曄姺張棟偝傟偰偄傑偡丅
暥帤敳偗丒暥帤壔
僐儞僺儏乕僞偵擖椡偝傟偨暥帤偼乽暥帤僐乕僪乿偵廬偭偰,奩摉偺暥帤傪昞帵,報帤,婰榐偟傑偡丅僐儞僺儏乕僞娫偱惓偟偄僨乕僞偺傗傝庢傝偑偱偒偰傕,暥帤僐乕僪偺婯奿偼暋悢偁傞偨傔,僷僜僐儞摨巑偺巊梡乽暥帤僐乕僪懱宯乿偑堦抳偟偰偄側偄偲暥帤壔偗傗寚棊側偳偺晄搒崌偑婲偒傑偡丅尰嵼偼僜僼僩僂僄傾儗儀儖偱,暥帤僐乕僪偺堘偄傪懳墳挷惍偱偒傞傛偆偵側偭偰偄傑偡偑,偆傑偔摦嶌偟側偄偙偲傕偁傝傑偡丅
暥帤敳偗傗暥帤壔偑婲偒偨応崌偼,嵟弶偵僜僼僩僂僄傾偺暥帤僐乕僪愝掕傪妋擣偟傑偡丅擔杮偱偼,擔杮岅暥帤僐乕僪偵乽僔僼僩JIS僐乕僪乿傪昗弨偲偟偰巊偄傑偡偑,懠偺傕偺偼巊傢側偄偲偄偆偙偲偱偼偁傝傑偣傫丅Web儁乕僕偵偼乽Unicode乿傗乽EUC乿偑婎弨偵側傝傑偡丅
捠忢,暥帤僐乕僪巜掕偼昗弨愝掕乮僨僼僅儖僩乯偺傑傑巊梡偟傑偡偑,暥帤僐乕僪愝掕乮僄儞僐乕僪乯偑僔僼僩JIS側偳偵屌掕偝傟偰偄傞偲巚傢偸暥帤昞帵僄儔乕偑婲偒傞偙偲偑偁傝傑偡丅僜僼僩僂僄傾儗儀儖偺暥帤僐乕僪愝掕乮僄儞僐乕僪乯偼乽帺摦慖戰乿傪桳岠偵偟偰偍偔偙偲傪偍偡偡傔偟傑偡丅
庡側暥帤僐乕僪懱宯
俰俬俽僐乕僪 JIScode
擔杮岺嬈婯奿乮JIS乯偱惂掕偟偨娍帤傪拞怱偲偡傞暥帤僐乕僪懱宯偱偡丅惓幃柤徧偼乽忣曬岎姺梡娍帤晞崋宯乿偲偄偄傑偡丅俰俬俽僐乕僪偼偄偔偮偐偺夵掶婯奿偑偁傝,柤徧偼乽JIS X0208:1997乿偺宍幃偱偁傜傢偟傑偡丅乽X0208乿偼夵掶撪梕,乽1997乿偼夵掶擭傪偁傜傢偟傑偡丅
俙俶俲暥帤丂傾儞僋傕偠 alphanumeric and kana character
俰俬俽僐乕僪乮JIS X0201乯偵8價僢僩乮1僶僀僩乯偺僐乕僪偱妱傝摉偰傜傟偰偄傞塸悢帤(Alpha)丒婰崋(Numeric),僇僞僇僫(Kana)偺偙偲傪偄偄傑偡丅偙偺僐乕僪偱昞帵偝傟傞暥帤傪捠忢乽敿妏暥帤乿偲偄偄傑偡丅
俰俬俽娍帤僐乕僪
俰俬俽僐乕僪偺娍帤僐乕僪晹暘傪偄偄傑偡丅娍帤僐乕僪偼巊梡昿搙偵傛傝,戞堦悈弨,戞擇悈弨側偳偺嬫暘偗偑偝傟偰偄傑偡丅戞侾悈弨偼婎杮揑側娍帤,戞俀悈弨偼恖柤側偳偺屌桳柤帉偺娍帤偵側傝傑偡丅
戞侾悈弨偲戞俀悈弨偱,堦斒揑側帠柋暥復側傜偽嵟掅尷偺傕偺偼偱偒傑偡偑,恖柤丒抧柤娍帤側偳側偄傕偺偑偁傝,奜帤婡擻偱偮偔傞昁梫偑偁傝傑偟偨丅奜帤婡擻偱嶌偭偨暥帤偼奺巊梡幰偑帺暘偺僷僜僐儞偱撈帺偵捛壛偟偨暥帤偱偡丅摨偠奜帤搊榐僼傽僀儖傪巊梡偟側偄偲懠偺僷僜僐儞偱偼昞帵偱偒側偄偲偄偆栤戣偑偁傝傑偡丅
僷僜僐儞偺晛媦偵敽偄峴惌,朄棩,嬥梈,妛弍尋媶,妛峑,彜幮側偳偄傠偄傠側暘栰偱巊偆暥帤偺昁梫惈偑惗傑傟,JIS X0213偲偟偰俰俬俽戞俁悈弨,戞係悈弨偑惂掕偝傟,偝傜偵屆揟偱巊傢傟傞媽帤懱側偳傪搊榐偟偨奼挘娍帤乮曗彆娍帤乯傕惂掕偝傟傑偟偨丅
ISO-2022-jp
ASCII僐乕僪偺塸悢帤偲JIS X0208偺擔杮岅乮娍帤乯傪嫟懚偱偒傞傛偆偵偟偨婯奿偱偡丅ASCII僐乕僪偲摨偠俈價僢僩僐乕僪偱擔杮岅傕婯掕偟傑偡丅偨偩偟,偙偺傑傑偱偼奩摉僐乕僪偑塸悢帤偐擔杮岅偐偺敾抐偱偒側偔側傝傑偡偺偱,暥帤僐乕僪偑愗傝懼傢傞応強偵惂屼僐乕僪乮僄僗働乕僾僔乕働儞僗乯傪憓擖偟敾抐偟傑偡丅
乽ISO-2022-jp乿偼乽ISO-2022乿傪擔杮岺嬈婯奿乮JIS乯偑奼挘婯掕偟偨傕偺偱偡丅乽ISO-乿偲側偭偰偄傑偡偑,乽ISO(傾僀僄僗僆乕)崙嵺昗弨壔婡峔乿偺婯奿偱偼偁傝傑偣傫丅乽ISO-2022-jp乿傪乽JIS僐乕僪乿偲屇傇偙偲傕偁傝傑偡丅E儊乕儖偱偼偙偺暥帤僐乕僪僙僢僩傪巊偭偰偄傑偡丅
僔僼僩俰俬俽僐乕僪 shift JIScode
JIS僐乕僪偼,ASSICI僐乕僪偲廳暋偡傞晹暘偑偁傞偨傔,娍帤僐乕僪傪俉價僢僩偱妱傝摉偰捈偟偨傕偺偑僔僼僩JIS僐乕僪偱偡丅侾僶僀僩暥帤偲俀僶僀僩暥帤偑崿嵼偟偰傕敾暿偱偒傞傛偆偵婯掕偝傟偰偄傑偡丅
偙偺僐乕僪偼儅僀僋儘僜僼僩幮偑奐敪偟偨傕偺偱偡偺偱,僷僜僐儞婎杮僜僼僩乮俷俽乯偺MS-DOS傗Windows偱嵦梡偝傟偰偄傑偡丅偙偺偨傔尰嵼偺擔杮偺僷僜僐儞偱偼乽僔僼僩俰俬俽僐乕僪乿偑昗弨偲側傝傑偡丅
倀値倝們倧倓倕丂儐僯僐乕僪
暷崙婇嬈偑拞怱偵側偭偰愝棫偟偨儐僯僐乕僪僐儞僜乕僔傾儉偑採埬偟偨暥帤僐乕僪婯掕偱偡丅塸岅側偳傾儖僼傽儀僢僩傪巊梡偡傞尵岅偼1暥帤傪1僶僀僩偱昞尰偱偒傑偡偑,擔杮岅傗拞崙岅偱巊偆娍帤傗傾儔價傾岅偺傾儔價傾暥帤側偳偼1僶僀僩偱偼昞尰偱偒傑偣傫丅
悽奅奺崙偺暥帤懱宯偵懳墳偱偒傞傛偆偵,偡傋偰偺暥帤傪俀僶僀僩偱昞偟偨暥帤僐乕僪懱宯偱偡丅傾儖僼傽儀僢僩傗娍帤側偳傪摑堦揑偵庢傝埖偆偙偲傪栚揑偲偟偰偄傑偡丅偨偩偟娍帤偵偮偄偰偼帤宍偑帡偄傞傕偺偑傂偲偮僐乕僪偵摑堦偝傟偰偄傞偨傔擔杮岅偲拞崙岅偱栤戣傪惗偠傞偙偲偑偁傝傑偡丅
乽Unicode(儐僯僐乕僪)乿偵偼擖弌椡曄姺曽幃偺堘偄偵傛傝UTF-7,UTF-8,UTF-16偺俁偮偑偁傝傑偡丅
俤倀俠丂僀乕儐乕僔乕 extended UNIX code
暷俙俿仌俿幮偑嶔掕偟偨倀俶俬倃梡偺崙嵺壔懳墳婯奿偱偡丅奼挘倀俶俬倃僐乕僪偲傕偄偄傑偡丅擔杮岅,娯崙岅,拞崙岅側偳傕掕傔傜傟偰偄傞儅儖僠僶僀僩偺暥帤僐乕僪懱宯偱偡丅僒乕僶乕側偳婎杮僜僼僩乮俷俽乯偵倀俶俬倃傪巊梡偟偰偄傞応崌偵巊傢傟傑偡丅
乽俤倀俠(僀乕儐乕僔乕)乿偵偼擔杮岅EUC(EUC-JP),娯崙岅EUC(EUC-KR)側偳偑偁傝傑偡丅